用通俗易懂的语言谈谈统计机器学习中的逻辑斯谛回归。
逻辑回归是统计机器学习中的经典分类算法,那么首先来说说分类问题。
分类问题
分类问题(Classification Problem)的本质是:
- 学习输入到输出的映射 \(f:X\to Y\)
- \(X\): 输入
- \(Y\): 输出
这样的映射关系其实可以通过一个条件概率 \(P(Y|X)\) 来表达。即给定一个 \(X\),结果是 \(Y\) 的概率是多少?如果一个真实值是 \(X=3,Y=1\),那么我们希望 \(P(Y=1|X=3)\) 的值越大越好。
逻辑回归的核心就是我们怎么定义出这个 \(P(Y|X)\)?
一旦 \(P(Y|X)\) 定义出来,我们就可以基于这个概率,给输入的数据做分类。比如说,给定 \(X=5\),如果 \(P(Y=1|X=5) > P(Y=0|X=5)\),那么就应该分类到 \(Y=1\) 所表示的部分。
定义逻辑回归
线性回归?
我们可不可以用线性回归来表示呢?即 \(P(Y|X) = w^T x + b\)。
我们从概率角度思考。\(P(Y|X)\) 应该满足下面的条件:
- \(0 \le P(Y|X) \le 1\)
- \(\sum_y P(Y|X) = 1\)
但是,\(-\infty \le w^T x + b \le +\infty\), (\(x\in R^d\))。所以显然不满足条件概率的定义。
那么,我们有没有办法把 \(w^T x + b\) 的范围映射到 \([0,1]\) 呢?
逻辑函数?
我们先来看看一个重要概念:逻辑函数(Logistic Function)。它长这个样子:
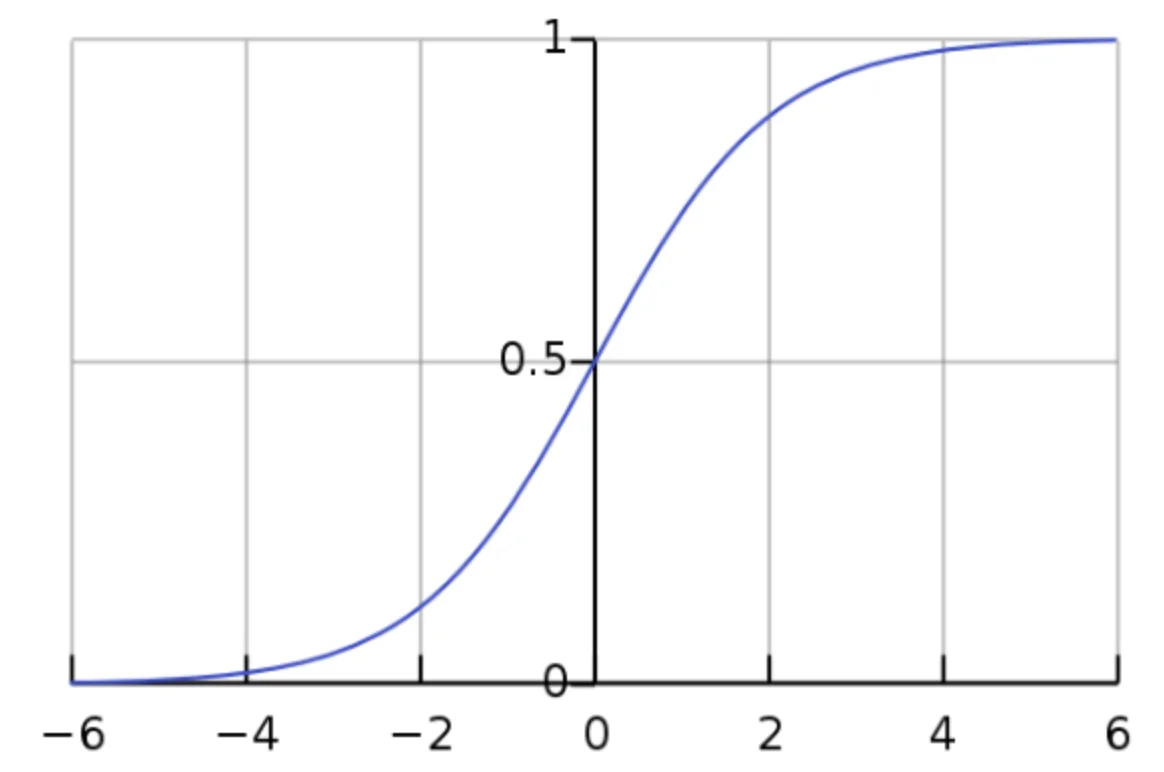
- 值域:\((0,1)\)
- 定义域:\((-\infty,+\infty)\)
- (从图中可以注意到,当 \(x>6\) 时,\(y\) 几乎等于 \(1\) 了,反之同理。)
因为形状很像 S,所以它属于 S 函数(Sigmoid Function / Sigmoid Curve)。S 函数有很多种,逻辑函数是最常见的一种。
逻辑函数的定义是: \[ y = \sigma (x) = \frac{1}{1+e^{-x}} = \frac{e^{-x}}{e^{-x}+1} \]
这里的 \(\sigma\) 即 sigmoid 之意。
逻辑函数 + 线性回归 = 逻辑回归
既然逻辑函数的性质之一是值域落在 \((0,1)\),我们有没有可能利用它来改进线性回归 \(w^T x +b\),让它的值域也映射到 \((0,1)\) 区间内呢?
我们发现,逻辑函数 \(\sigma\) 和线性回归函数 \(w^T x +b\) 的共性之一是:\(\sigma\) 定义域和 \(w^T x +b\) 的值域都是 \((-\infty,+\infty)\)。那么我们把后者的值域映射成前者的定义域就可以了。
也就是说: \[ P(y|x;w) = \sigma (w^Tx + b) = \frac{1}{1+e^{-(w^T x + b)}} \]
举个例子
| 年龄 | 工资 | 学历 | (还款)逾期 |
|---|---|---|---|
| 20 | 4000 | 本科 | YES |
| 25 | 5000 | 专科 | NO |
| 21 | 6000 | 本科 | NO |
| 25 | 5000 | 专科 | YES |
| 28 | 8000 | 本科 | NO |
| 27 | 7000 | 本科 | ? |
比如,针对第一个样本:
- \(x^{(1)} = \begin{bmatrix} 20 \newline 4000 \newline 本科 \end{bmatrix}\)
- \(w = \begin{bmatrix} w_0 \newline w_1 \newline w_2 \end{bmatrix}\),(因为有三个参数,所以也需要三个 \(w\))
- \(b \in R\)
那么有: \[ P(Y = \text{Yes} | x^{1}) = \frac{1}{1+e^{-(\begin{bmatrix} w_0 & w_1 & w_2 \end{bmatrix} \begin{bmatrix} 20 \newline 4000 \newline 本科 \end{bmatrix} + b)}} \] 其他样本依次类推。如此一来,根据这么多样本,我们可以估计出 \(w\) 和 \(b\),来计算未知样本的 \(y\)。
如何估计呢?
在求 \(w\) 和 \(b\) 前的预备知识
逻辑回归的决策边界
在求 \(w\) 和 \(b\) 前,我们先要认识这个道理:逻辑回归函数是线性分类器(Linear Classifier)。
判断一个函数或模型是线性还是非线性的,核心在于判断它的决策边界(Decision Boundary)。
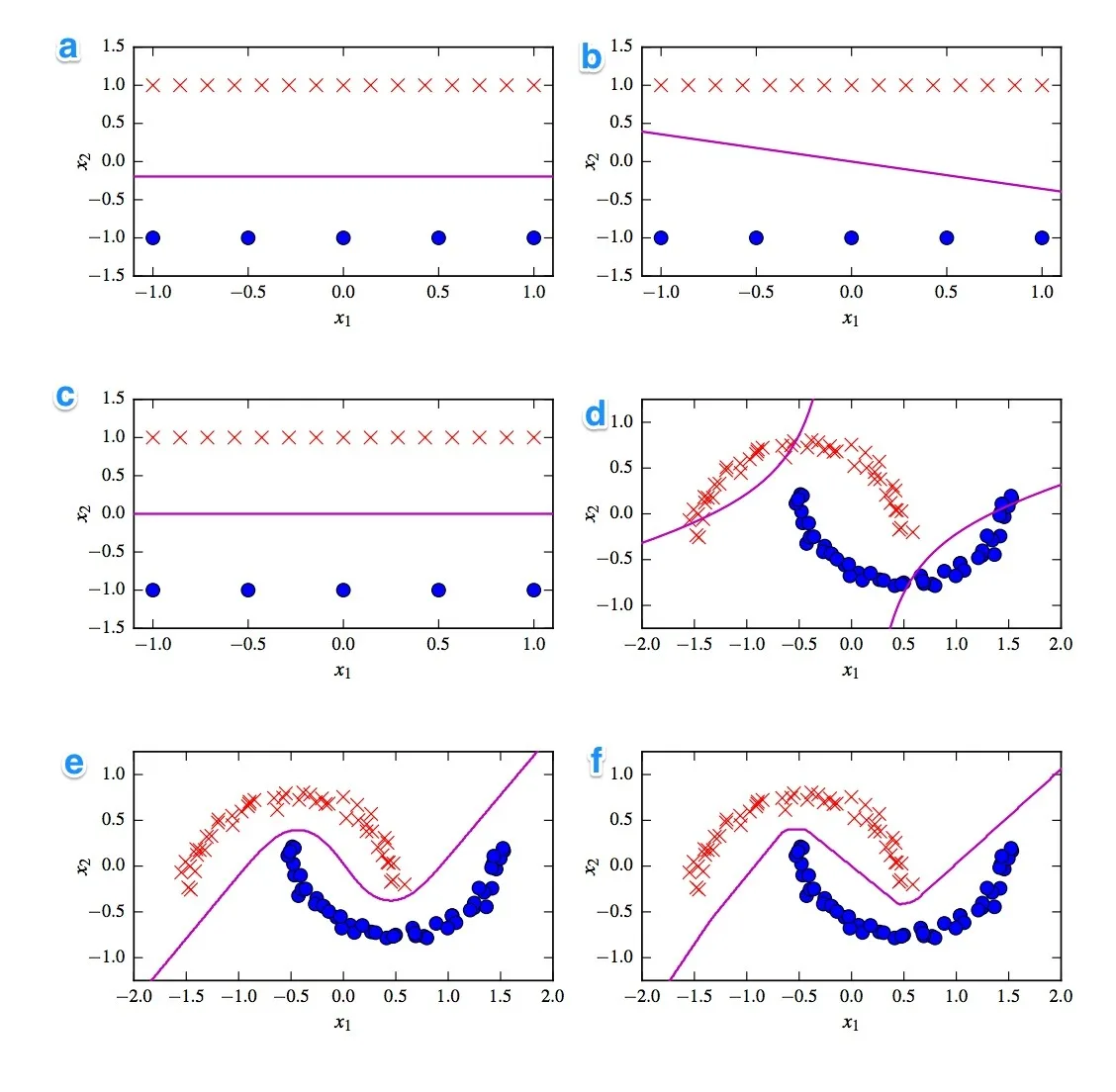
比如上面这幅图中,紫色函数线即决策边界。a b c 是线性,d e f 是非线性。
决策边界怎么求呢?求法是基于这样一个性质:落在决策边界上的点,对于两边的概率是相等的,即 \(P(y=0|x,w) = P(y=1|x,w)\)。
基于: \[ \begin{align} P(y = 1 |x,w) &= \frac{1}{1+e^{-(w^T x + b)}} \\ \\ P(y = 0 |x,w) &= 1 - P(y = 1 |x,w) \\ & = \frac{e^{-(w^T x + b)}}{1+e^{-(w^T x + b)}} \end{align} \]
两个式子可以合并成:\(P(y|x,w) = P(y=1|x,w)^y [1-P(y=1|x,w)]^{1-y}\)。我们后面会用到这个式子。
我们把上面两个式子代入到 \(P(y=0|x,w) = P(y=1|x,w)\): \[ \begin{align} \frac{e^{-(w^T x + b)}}{1+e^{-(w^T x + b)}} &= \frac{1}{1+e^{-(w^T x + b)}} \\ e^{-(w^T x + b)} &= 1 \\ \ln e^{-(w^T x + b)} &= \ln 1 \\ -(w^T x+b) &= 0 \\ w^T x+b &= 0 \end{align} \] 那么最后的 \(w^T x+b = 0\) 就是逻辑回归的决策边界。它是线性的。
目标函数
知道了这些,我们再来求 \(w\) 和 \(b\)。
求 \(w\) 和 \(b\) 的依据是一个目标函数(Objective Function)。每一个模型都对应着一个目标函数,即我们想最大化/最优化的一个函数。我们再沿着这个函数,找出最优解。
模型的实例化相当于定义一个明确的目标函数。有了目标函数,再通过优化算法(如 SGD、AdaGrad、Adam……),求出最优解。
对于逻辑回归模型,优化目标是最大似然估计(Maximum Likelihood Estimation,缩写为 MLE)。
假设我们拥有数据集 \(D = \{ (x_i, y_i) \}^{n}_{i=1}\),\(x \in R^d, y \in \{0,1\}\)。\(n\) 表示样本总数。我们需要最大化这样一个目标函数: \[ \hat w_{MLE}, \hat b_{MLE} = \arg\max_{w,b} \prod^n_{i=1} P(y_i|x_i, w,b) \] 这里的 \(P(y_i|x_i, w,b)\) 就是单个样本的条件概率,也就是之前所说的合并式 \(P(y|x,w) = P(y=1|x,w)^y [1-P(y=1|x,w)]^{1-y}\)。\(\prod^n_{i=1} P(y_i|x_i, w,b)\) 就是每一个样本的条件概率的乘积。\(\operatorname{argmax}_{w,b}\) 指的是让右边这个式子最大化的 \(w\) 和 \(b\)。
比如,\(\hat x = \arg\max_x f(x)\) 的意思就是找到一个 \(x\) 的值,让 \(f(x)\) 最大化。
现在,我们可以来求最优的 \(w\) 和 \(b\) 了。不过先进行一个简化: \[ \begin{align} \hat w_{MLE}, \hat b_{MLE} &= \arg\max_{w,b} \prod^n_{i=1} P(y_i|x_i, w,b) \\ &= \arg\max_{w,b} \log [\prod^n_{i=1} P(y_i|x_i, w,b)] \\ &= \arg\max_{w,b} \sum^n_{i=1} \log P(y_i|x_i, w,b) \\ &= \arg\min_{w,b} - \sum^n_{i=1} \log P(y_i|x_i, w,b) \end{align} \] 为什么我们要加 \(\log\) 呢?理由是这样的。概率一般在 \((0,1)\) 之间。这么多概率相乘后,结果会非常非常小,计算机不能处理如此「精准」的小数,导致下溢(underflow)。所以加上之后,再利用 \(\log(xyz) = \log x+\log y +\log z\) 这个性质,把相乘变为相加,解决这个问题。
我们把 \(P(y|x,w) = P(y=1|x,w)^y [1-P(y=1|x,w)]^{1-y}\) 代入看看: \[ \begin{align} \hat w_{MLE}, \hat b_{MLE} &= \arg\min_{w,b} - \sum^n_{i=1} \ln P(y_i|x_i, w,b) \\ &= \arg\min_{w,b} - \sum^n_{i=1} \log [P(y_i=1|x_i,w)^{y_i} [1-P(y_i=1|x_i,w)]^{1-y_i}] \\ &= \arg\min_{w,b} - \sum^n_{i=1} y_i \log P(y_i=1|x_i,w) + (1-y_i) \log [1-P(y_i=1|x_i,w)] \\ &= \arg\min_{w,b} - \sum^n_{i=1} y_i \log \sigma(w^T x_i + b) + (1-y_i) \log [1 - \sigma(w^T x_i + b)] \end{align} \] 所以现在问题转化成求解 \(\arg\min_{w,b} - \sum^n_{i=1} y_i \log \sigma(w^T x_i + b) + (1-y_i) \log [1 - \sigma(w^T x_i + b)]\)。
求最优的 \(w\) 和 \(b\) 的方法
凸函数
在求最优时,我们要考虑一个问题,它是全局最优(Global Optimal)还是局部最优(Local Optimal)?
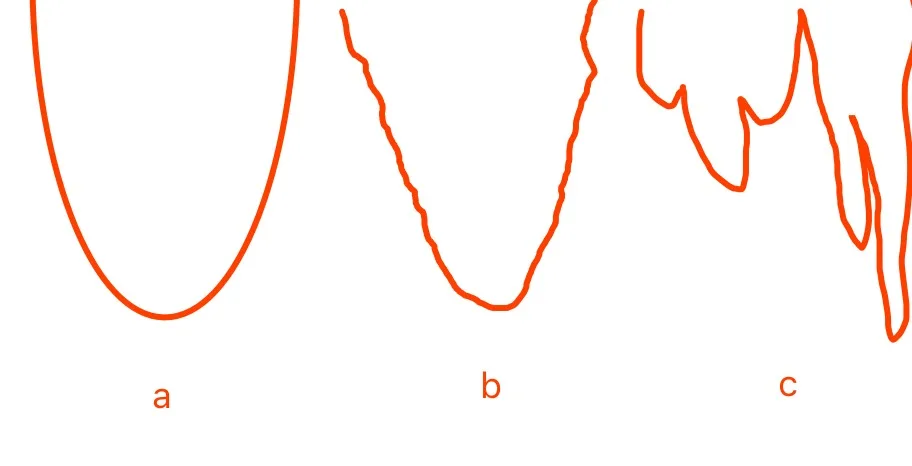
这里,a b 都属于凸函数(Convex Function),c 是非凸函数(Non-Convex Function),凸函数通过优化算法得出的解一定是全局最优,而非凸函数则可能会得出局部最优解。
b 严格说是不变凸函数(Invex Function),一种凸函数的通型。
神经网络是很典型的非凸函数。
如何判断一个函数是不是凸函数呢?
凸集
我们首先给出凸集(Convex Set)的定义:对于任意 \(x,y\in C\),任意参数 \(\alpha \in [0,1]\),都有 \(\alpha x +(1-\alpha)y \in C\),则集合 \(C\) 为凸集。
直观上说,它是一个点集合,其中每两点之间的直线点都落在该点集合中。
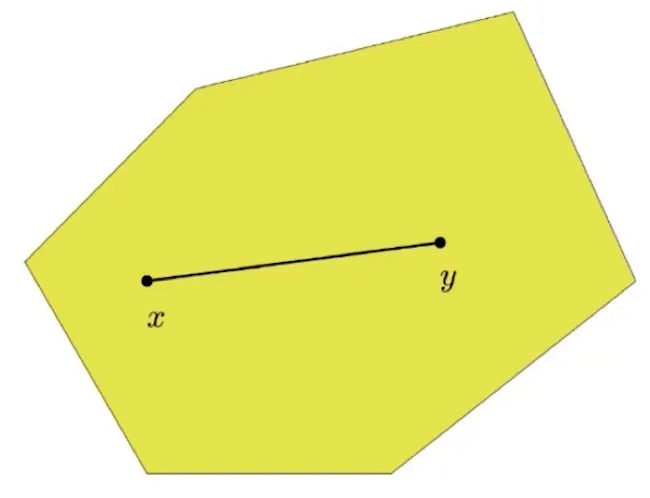
以图片为例,黄色区域是 \(C\),选择任意两点 \(x,y\),上面任何两点的连线(即 \(\alpha x +(1-\alpha)y\))都在 \(C\) 内,这个就是凸集。
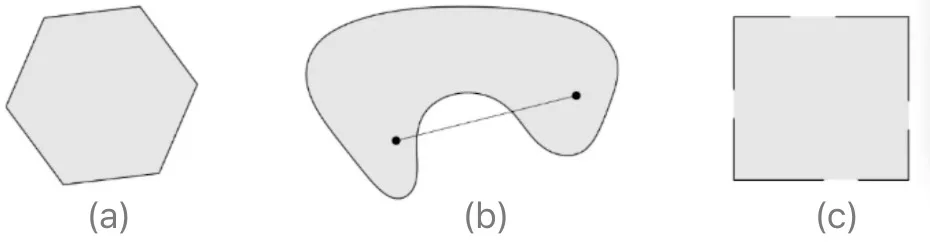
上图,(a) 是凸集,(b) (c) 都是非凸集。
凸集的例子:
- \(R^n\)
- 范数 \(||x|| \le 1\)
- Affine set \(Ax = b\)
- Halfspace \(Ax \le b\)
两个凸集的交集也是凸集。
凸函数
如果一个函数 \(f\) 的定义域为凸集,对于定义域内任意 \(x,y\),和任意参数 \(\alpha \in [0,1],\)都有 \(f(\alpha x+ (1-\alpha)y) \le \alpha f(x) + (1-\alpha)f(y)\),那么这个函数就是凸函数。
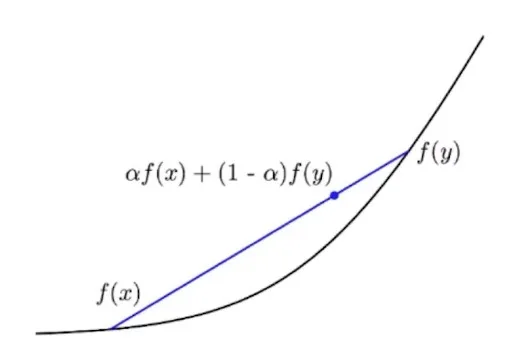
凸函数的例子:
- 线性函数是凸/凹函数
- \(e^x, -\log x, x\log x\)
- 范数
- \(\frac{x^Tx}{t}\)
凸函数的判断
除了根据定义外,还有很多种方法可以判断函数是否是凸函数。
First Order Convexity Condition
假设 \(f: R^n \to R\) 可导(differentiable),对于任意 \(x,y\in D(f)\)(定义域),当且仅当 \(f(y) \geq f(x)+\nabla f(x)^{T}(y-x)\) 时,函数是凸函数。
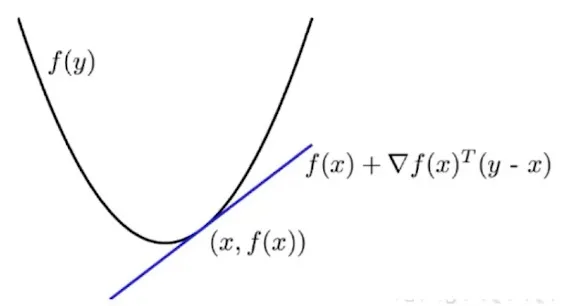
Second Order Convexity Condition
假设 \(f: R^n \to R\) 两次可导(twice differentiable)对于任意 \(x,y\in D(f)\)(定义域),当且仅当 \(\nabla^{2} f(x) \geq 0\) 时,函数是凸函数。
方法一:\(f'(w)=0\)?
求使得 \(f(w)\) 值最小的参数 \(w\) 应该怎么找呢?
一个最简单的办法就是求导,令 \(f'(w) = 0\),求出 \(w\)。
但是对于复杂函数,这种方法就很难求了。我们用的是另一种方法,迭代式(Iterator)求解。
方法二:Iterator
迭代法的一些典型算法有:Gradient Descent、Stochastic Descent、AdaGrad、Adam……
我们下面来讲一讲……
梯度下降法
基本思路
梯度下降法(Gradient Descent)的想法很简单——初始化一个参数,然后通过移动,一步步逼近最优解。
具体来说,要求使得 \(f(w)\) 值最小的参数 \(w\):
初始化 \(w^1\)
\(\text{for}\ t=1,2,3...\):
\(\ \ w^{t+1} = w^t - \eta \nabla f(w^t)\)
这里的 \(\eta\),我们称之为步长(Learning Rate)。步长过小,时间成本高;步长过长,可能无法收敛。
实践中,\(\eta\) 有时也写作 \(\eta_t\),它也会随着时间慢慢变小。
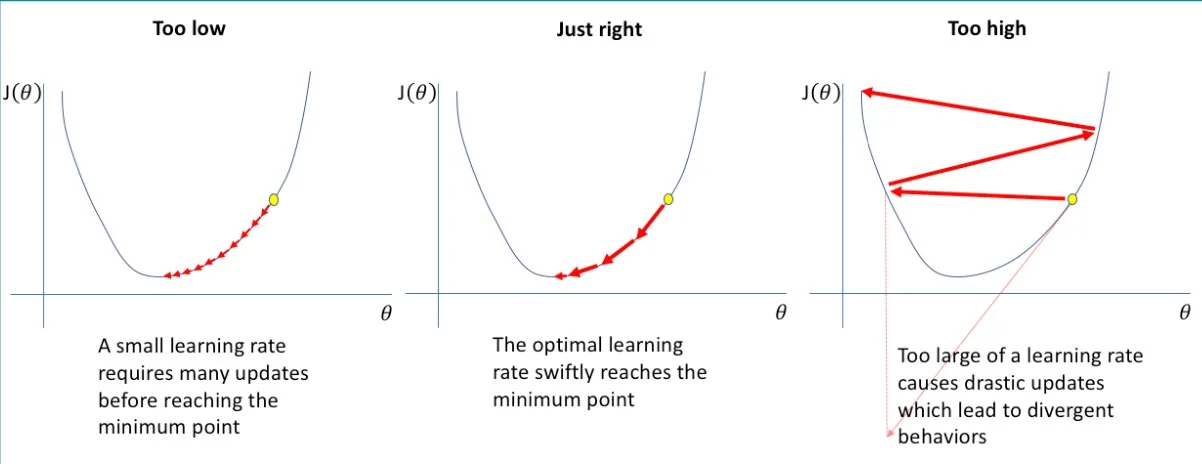
这里的 \(\nabla f(w^t)\),即当前梯度(Derivative)。它告诉了我们沿着哪个方向前进。
举个例子
求 \(f(w) = 4w^2+5w+1\) 的最优解。
很显然,答案是 \(-\frac{5}{8}\),但我们用梯度下降法来做一下。
- 令 \(\eta = 0.1\)
- 初始化随机参数:\(w^1 = 0\), \(f'(w) = 8w+5\)
- \(w^2 = w^1 - 0.1\times(8 \times w^1+5) = -0.5\)
- \(w^3 = w^2 - 0.1\times(8 \times w^2+5) = -0.6\)
- \(w^4 = ... = -0.62\)
- \(w^5 = ... = -0.625\)
求逻辑回归的最优解
回顾一下我们之前给逻辑回归定义的目标函数: \[ \arg\min_{w,b} - \sum^n_{i=1} y_i \log \sigma(w^T x_i + b) + (1-y_i) \log [1 - \sigma(w^T x_i + b)] \] 为了方便起见,我们定义右边一坨为 \(L(w,b)\): \[ L(w,b) = - \sum^n_{i=1} y_i \log \sigma(w^T x_i + b) + (1-y_i) \log [1 - \sigma(w^T x_i + b)] \] 对 \(L(w,b)\) 分别进行 \(w\) 和 \(b\) 的偏求导。 \[ \begin{align} \frac{\partial L (w,b)}{\partial w} &= - \sum^n_{i=1} y_i \frac{\sigma(w^T x_i + b) [1-\sigma(w^T x_i + b)]}{\sigma(w^T x_i + b)} x_i + (1-y_i) \frac{-\sigma(w^T x_i + b) [1-\sigma(w^T x_i + b)]}{[1 - \sigma(w^T x_i + b)]} x_i \\ &= - \sum^n_{i=1} y_i [1-\sigma(w^T x_i + b)] x_i + (y_i - 1) \sigma(w^T x_i + b) x_i \\ &= - \sum^n_{i=1} [y_i - \sigma(w^T x_i + b)] x_i \\ &= \sum^n_{i=1} [\sigma(w^T x_i + b) - y_i] x_i \end{align} \]
\[ \begin{align} \frac{\partial L (w,b)}{\partial b} &= - \sum^n_{i=1} y_i \frac{\sigma(w^T x_i + b) [1-\sigma(w^T x_i + b)]}{\sigma(w^T x_i + b)} + (1-y_i) \frac{-\sigma(w^T x_i + b) [1-\sigma(w^T x_i + b)]}{[1 - \sigma(w^T x_i + b)]}\\ &= - \sum^n_{i=1} y_i [1-\sigma(w^T x_i + b)] + (y_i - 1) \sigma(w^T x_i + b) \\ &= - \sum^n_{i=1} [y_i - \sigma(w^T x_i + b)] \\ &= \sum^n_{i=1} [\sigma(w^T x_i + b) - y_i] \end{align} \]
这里,最后结果中的 \(\sigma(w^T x_i + b)\) 是 \(P(y=1|x,w)\),即预测值,而 \(y_i\) 是真实值。也就是说我们每一步观察预测值和真实值的差,当差为 \(0\) 时,二者一样。
所以,求逻辑回归的最优解,梯度下降的做法是这样:
- 初始化 \(w^1,b^1\)
- \(\text{for}\ t=1,2,3...\):
- \(w^{t+1} = w^t - \eta \sum ^n_{i=1} [\sigma(w^T x_i + b) - y_i] x_i\)
- \(b^{t+1} = b^t - \eta \sum^n_{i=1} [\sigma(w^T x_i + b) - y_i]\)
停止迭代可以有不同的条件:
- \(L^t(w,b) - L^{t+1}(w,b) < \epsilon\)
- \(w^t-w^{t+1}\) 没有变化
- Early stopping: validation (验证集的准确性达到要求)
- Fixed iteration(固定 xx 步内)
梯度下降法的问题
每次迭代的时候,\(\sum^n_{i=1}\) 其实会导致效率问题:每次循环,我们都要计算针对所有样本的梯度,所以复杂度是 \(O(n)\)。随着样本数量上升,复杂度线性增长。
所以针对大数据,梯度下降法可能不是很合适。
复杂度分析
不同于一般算法,如果要分析迭代式算法的复杂度,我们需要利用收敛分析(Convergence Analysis),即分析多久函数会收敛。
\(L\)-Lipschitz 介绍
假设函数满足 \(L\)-Lipschitz 条件,并且是凸函数,设定 \(x^* = \operatorname{argmin} f(x)\)。那么对于步长 \(\eta_t \le \frac{1}{L}\),满足: \[ f\left(x_{k}\right) \leq f\left(x^{*}\right)+\frac{\left\|x_{0}-x^{*}\right\|_{2}^{2}}{2 \eta_{t} k} \]
- \(x_k\): 第 \(k\) 次迭代的 \(x\)
- \(x^*\): 最优时的 \(x\)
- \(\frac{\left\|x_{0}-x^{*}\right\|_{2}^{2}}{2 \eta_{t} k}\): 该项越小,\(x_k\) 越接近 \(x^*\)。它在迭代中变小得越快,说明这个算法越优质。
当迭代 \(k=\frac{L\left\|x_{0}-x^{*}\right\|_{2}^{2}}{\epsilon}\) 次后,可以保证得到 \(\epsilon\text {-approximation optimal value } \mathrm{x}\left(\eta_{t}=\frac{1}{L}\right)\)。即此时 \(f\left(x_{k}\right) \leq f\left(x^{*}\right)+\frac{\epsilon}{2}\)。\(\epsilon\) 就是目前和最优的差距。
关于 \(L\)-Lipschitz
对于一个函数 \(f: A \rightarrow \mathbb{R}^{m}, A \subset \mathbb{R}^{n}\) ,如果对于任何点 \(a, b \in A\),都有 \(|f(a)-f(b)| \leq L|a-b|\),(\(L \gt 0\)),那么我们说这个函数是 \(L\)-Lipschitz 的,或者直接称它是 Lipschitz(利普希茨)的。
直觉上,Lipschitz 函数限制了函数改变的速度,符合 Lipschitz 条件的函数的斜率,必小于一个称为 Lipschitz 常数 \(L\) 的实数(该常数依函数而定)。
线性回归和逻辑回归都满足 \(L\)-Lipschitz 和凸函数这两个条件。
\(L\)-Lipschitz 定理一
一个满足 \(L\)-Lipschitz 的函数,对于任意 \(x,y\in R^d\),有: \[ \|\nabla f(x)-\nabla f(y)\| \leq L\|x-y\| \] 举个线性回归的例子,\(f(w) = \frac{1}{n}||Xw-y||^2\)。 \[ \begin{align*} \|\nabla f(w_1)-\nabla f(w_2)\| &= \frac{2}{n} \| x^T(Xw_1-y) - x^T(Xw_2-y) \| \\ &= \frac{2}{n} \| x^T x (w_1-w_2) \| \\ &\le \frac{2}{n} \| x^T x \| \cdot|| (w_1-w_2) \| \end{align*} \] 于是 \(L = \| x^T x \|\)。
\(L\)-Lipschitz 定理二
一个满足 \(L\)-Lipschitz 的凸函数,对于任意 \(x,y\in R^d\),有: \[ f(y) \leq f(x)+\nabla f(x)(y-x)+\frac{L}{2}\|y-x\|^{2} \] 这个式子怎么来的呢?首先回顾一个积分相关的知识:对于函数 \(h(x)\),有: \[ h(1)=h(0)+\int_{0}^{1} h^{\prime}(\tau) d \tau \] 利用这个性质,我们定义新函数: \[ h(\tau)=f(x+\tau(y-x)) \] 则有 \(h(1) = f(y)\),\(h(0) = f(x)\)。综上: \[ \begin{align*} f(y)&=f(x)+\int_{0}^{1} \nabla f(x+\tau(y-x)) \cdot(y-x) d \tau \\ &=f(x) + \nabla f(x)(y-x) + \int_{0}^{1}\left( \nabla f(x+\tau(y-x)) - \nabla f(x)\right) \cdot(y-x) d \tau \\ &\le f(x)+\nabla f(x)(y-x)+\int_{0}^{1} L \| \tau (y-x) \| \cdot (y-x) d \tau \\ &= f(x)+\nabla f(x)(y-x)+ \frac{L}{2}\|y-x\|^{2} \end{align*} \]
收敛性推导
根据上面的定理: \[ f(y) \le f(x)+\nabla f(x)(y-x)+ \frac{L}{2}\|y-x\|^{2} \] 于是有: \[ \begin{align*} f(x_{i+1}) &\le f(x_i)+\nabla f(x_i)(x_{i+1}-x_i)+ \frac{L}{2}\|x_{i+1}-x_i\|^{2} \\ &= f(x_i)+\nabla f(x_i) \cdot (-1) \cdot \eta_t \nabla f(x_i) + \frac{L}{2}\cdot \eta_t^2 \|\nabla f(x_i)\|^{2} \\ &= f(x_i) - \eta_t \| \nabla f(x_i)\|^2 +\frac{L}{2}\cdot \eta_t^2 \|\nabla f(x_i)\|^{2} \\ &= f(x_i) - \eta_t (1-\frac{L}{2}\cdot \eta_t^2) \|\nabla f(x_i)\|^2 \\ &\le f(x_i) - \frac{\eta_t}{2} \|\nabla f(x_i)\|^2 \\ &\le f(x^*) + \nabla f(x_i)(x_i - x^*) - \frac{\eta_t}{2} \|\nabla f(x_i)\|^2 \\ &= f(x^*) + \frac{x_i - x_{i+1}}{x_i - x^*} \cdot (x_i - x^*) - \frac{1}{2 \eta_t} \| x_i - x_{i+1}\|^2 \\ &= f(x^*) + \frac{1}{2 \eta_t} \| x_i - x^* \|^2 - \frac{1}{2 \eta_t} (\| x_i - x^*\|^2 - 2 \eta_t\nabla f(x_i)(x_i-x^*)+ \|\eta_t\nabla f(x_i)\|^2) \\ &= f(x^*) + \frac{1}{2 \eta_t} \| x_i - x^* \|^2 - \frac{1}{2 \eta_t} \|x_i - x^* - \eta_t \nabla f(x_i) \|^2 \\ &= f(x^*) + \frac{1}{2 \eta_t} \| x_i - x^* \|^2 - \frac{1}{2 \eta_t} \|x_i - x^* - (x_i-x_{i+1}) \|^2 \\ &= f(x^*) + \frac{1}{2 \eta_t} \| x_i - x^* \|^2 - \frac{1}{2 \eta_t} \|x_{i+1}- x^* \|^2 \\ &= f(x^*) + \frac{1}{2 \eta_t} (\| x_i - x^* \|^2 - \|x_{i+1}- x^* \|^2) \end{align*} \]
- 第二、七、九步是由 \(x_{i+1} = x_i - \eta_t \nabla f(x_i)\) 得来的
- 第五步是由 \(\eta_t \le \frac{1}{L}\) 得来的
- 这个式子 \(f(x_{i+1}) \le f(x_i) - \frac{\eta_t}{2} \|\nabla f(x_i)\|^2\),由于后一项大于 \(0\),可以保证 \(f(x_{i+1}) \le f(x_{i})\),也就是梯度下降法中,新更新的值一直在降低。
- 第六步是由 \(f(y) \geq f(x)+\nabla f(x)^{T}(y-x)\) 得来的(First Order Convexity Condition)
- 第八步之所以如此转换,是为了得到 \(a^2-2ab+b^2\) 的模式
即: \[ f (x_{i+1}) - f(x^*) \le \frac{1}{2 \eta_t} (\| x_i - x^* \|^2 - \|x_{i+1}- x^* \|^2) \] 也就是说: \[ \left\{\begin{array}{l}{f (x_{1}) - f(x^*) \le \frac{1}{2 \eta_t} (\| x_0 - x^* \|^2 - \|x_{1}- x^* \|^2) \\ f (x_{2}) - f(x^*) \le \frac{1}{2 \eta_t} (\| x_1 - x^* \|^2 - \|x_{2}- x^* \|^2) \\ \vdots \\ f (x_{k+1}) - f(x^*) \le\frac{1}{2 \eta_t} (\| x_k - x^* \|^2 - \|x_{k+1}- x^* \|^2) }\end{array}\right. \] 把上面式子们左右两边相加: \[ \begin{align*} \sum_{i=1}^{k} f(x_i) - k\cdot f(x^*) &\le \frac{1}{2 \eta_t} (\| x_0 - x^* \|^2 - \|x_{k}- x^* \|^2) \\ &\le \frac{1}{2 \eta_t}\| x_0 - x^* \|^2 \end{align*} \] 因为始终有 \(f(x_k) \le f(x_{k-1})\),所以: \[ \begin{align*} k \cdot f(x_k) - k\cdot f(x^*) &\le \sum_{i=1}^{k} f(x_i) - k\cdot f(x^*) \\ &\le \frac{1}{2 \eta_t}\| x_0 - x^* \|^2 \end{align*} \] 即: \[ f(x_k) - f(x^*) \le \frac{\| x_0 - x^* \|^2 }{2 \eta_t \cdot k} \]
这个研究领域叫 stochastic optimization.
随机梯度下降法
基本思路
随机梯度下降法(Stochastic Gradient Descent)就可以解决这个效率问题。它的思路很简单——每次更新只依赖其中一个样本,而不是全部。
- \(\text{for}\ iter=1,2,3,...,T\)
- \(\text{shuffle}(\{x_i,y_i\}_{i=1}^n)\) (重新排列所有样本)
- \(\text{for}\ i=1,2,3,...,n\):
- \(w^{new} = w^{old} - \eta [\sigma(w^T x_i + b) - y_i] x_i\)
- \(b^{new} = b^{old} - \eta [\sigma(w^T x_i + b) - y_i]\)
在实践中,随机梯度下降法用得更多一些。
随机梯度下降法的问题
每次计算出的梯度存在噪声。所以步长一般采用更小的步长,用来降低噪声。
Mini-Batch Gradient Descent
基本思路
梯度下降每次看所有样本(所以又叫 Batch Gradient Descent),随机梯度下降每次只看一个样本,是两个极端。而 Mini-Batch Gradient Descent 方法就是这两个极端的折中:每次从 n 个样本中随机选取 m 个样本。
过拟合
当数据线性可分
线性可分是指图像上可以有一条直线将不同类别数据分开,否则就是非线性可分。
当给定的数据线性可分时,逻辑回归的参数(\(\left| w \right|\), magnitude)会趋向于正无穷,为什么?
If data is linearly separable, then \(w\) goes to infinity.
\[ \begin{align} P(y = 1 |x,w) &= \frac{1}{1+e^{-(w^T x + b)}} \\ \\ P(y = 0 |x,w) &= 1 - P(y = 1 |x,w) \\ & = \frac{e^{-(w^T x + b)}}{1+e^{-(w^T x + b)}} \end{align} \]
观察式子,我们希望 \(P(y=1|x,w)\) 越大越好,即越趋近于 \(1\) 越好,即 \(e^{-(w^x+b)}\) 越趋近于 \(0\) 越好,即 \(w^Tx+b\) 越大越好,即 \(w\) 越大越好。
由于 \(w^T x+b\) 就是逻辑回归的决策边界,斜率 \(w\) 趋近无穷,导致决策边界的图像几乎垂直。
这种现象其实叫「过拟合」(Over-fitting)现象,训练出的模型并不是我们实际想要的。
如何避免这种现象呢?答案之一是「正则化」(Regularization)。
正则化
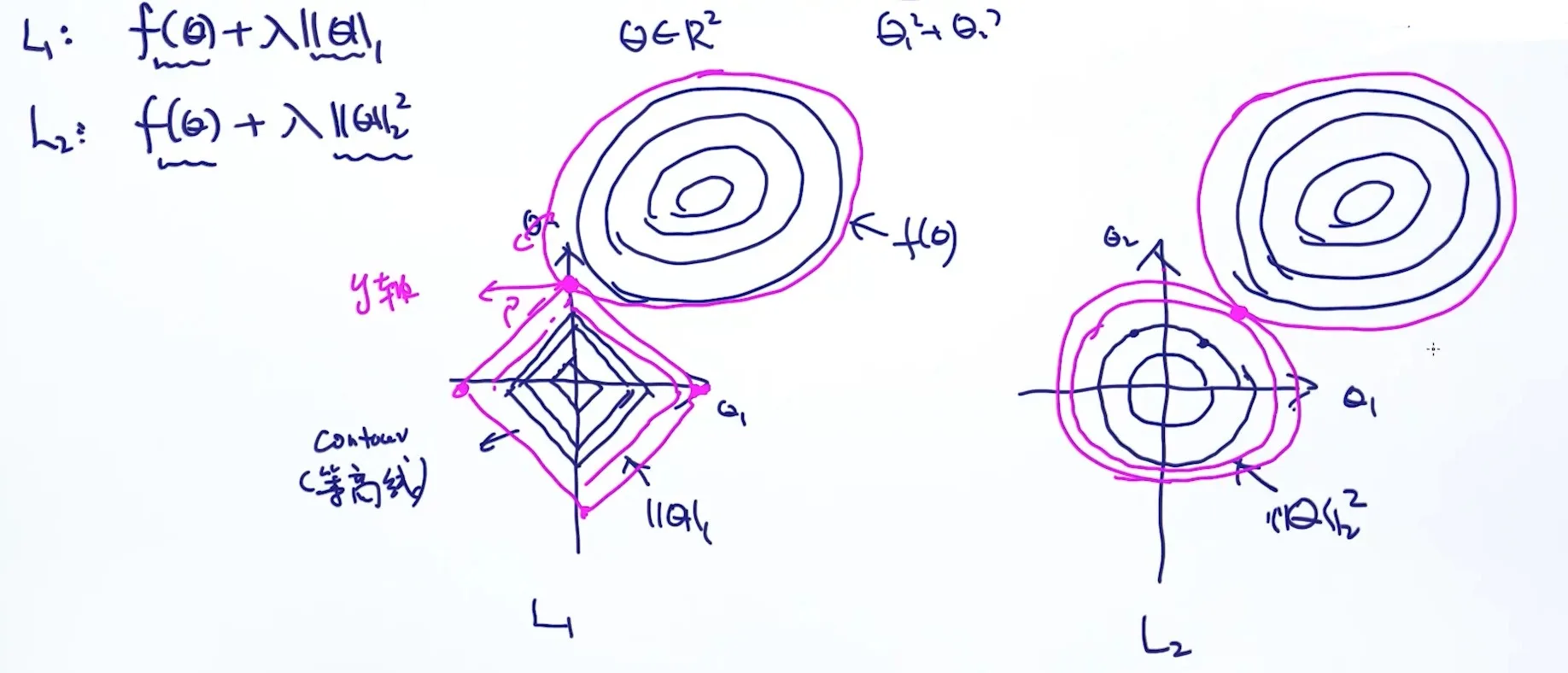
Adding a Term - L2 Norm
我们在之前求最优 \(w\) 和 \(b\) 的式子(目标函数)上加一个项,叫 L2 Norm: \[ \widehat{w}_{M L E,} \hat{b}_{M L E}= \operatorname{argmin}_{w, b} -\prod_{i=1}^{n} p\left(y_{i} | x_{i}, w\right)+\lambda\|w\|_{2}^{2} \]
\[ \|w\|_{2}^{2} = w_1^2 + w_2^2+ \cdots + w_n^2 \]
如果 \(w\) 很大,导致 \(\lambda\|w\|_{2}^{2}\) 也很大,违背了 \(\operatorname{argmin}\) 的意愿。换句话说,这里新加的一项就是用来控制 \(w\),不让它变大。
这里的 \(\lambda\) 叫「超参数」(Hyper-parameter),可以理解为一个 “weighting factor”,在前面项和后面项(即 L2 Norm)之间做个权衡。\(\lambda\) 越大,\(w\) 就被控制得越小;反之同理;而当 \(\lambda = 0\), \(w\) 无限制。
超参数,就是需要人工干预的参数。与之相对的是「模型参数」(Model Parameter),比如 \(w\)、\(b\)。

再来看看这个项对梯度下降的影响: \[ \begin{align} \frac{\partial L (w,b) + R(w)}{\partial w} &= \sum^n_{i=1} [\sigma(w^T x_i + b) - y_i] x_i + 2\lambda w\\ \end{align} \]
\[ \begin{align} \frac{\partial L (w,b) + R(w)}{\partial b} &= \sum^n_{i=1} [\sigma(w^T x_i + b) - y_i] \end{align} \]
其他范数
还有 L0 Norm、L1 Norm、Nuclear Norm……
Nuclear Norm 可以最小化矩阵的秩(Rank)。
L0 Norm 可以清算向量中非零的数字,即最小化向量中非零数的个数。
L1 vs L2
这里再重点说一下 L1 Norm。
L1 Norm 和 L2 Norm 类似,让 \(w\) 变小(事实上,L2 Norm 表现更好)。但除此之外,L1 Norm 还有一个特点——让很多 \(w\) 参数变为 \(0\),导致稀疏(induces sparse solution)。如果某个参数变为 \(0\),意味着它事实上对我们的决策没有帮助,可以去掉。所以 L1 Norm 某种程度上也起到一个筛选的作用。当有场景需要筛选一些表现糟糕或无相关的参数时,可以考虑 L1 Norm。
L1 Norm 的一个应用场景是,通过大脑中的神经元激活状态,判断这个人在想什么。我们知道,思考某件事时,只有大脑中一部分区域的神经元在处于活跃。这种情况下,我们会希望采用 L1 Norm 来让参数稀疏,筛选掉无用的神经元参数。
但是为什么 L1 Norm 会导致稀疏呢?可以从几何角度思考。

L1 + L2
我们上面说到,L2 最小化 \(w\) 的能力比 L1 强,L1 又拥有良好的稀疏能力。既然如此,为什么不能二者一起上呢?这个其实就叫「弹性网络」(Elastic Net)。
- 如果 \(f(w) = \sum_{i=1}^n (w^T x_i + b - y_i) ^2\)
- 那么 \(f(w) + \lambda_2 || w ||_1 + \lambda_2 ||w||_2^2\) 就叫 Elastic Net。
https://en.wikipedia.org/wiki/Elastic_net_regularization
L1 的另一个问题是,如果某些变量作用类似,我们希望去掉相关性大的「重复作用的」变量。L1 会帮我们随机地在一组类似中选择一项,而不是最好的那一项。但是 Elastic Net 却可以帮我们避免这个问题。为什么呢?请看论文。
交叉验证
如何确定正则的 \(\lambda\) 呢?方法就是交叉验证(Cross Validation)。
交叉验证,即把训练数据进一步分成训练数据(Training Data)和验证集(Validation Data),选择在验证数据里最好的超参数组合。

请注意,绝对不能用测试数据来引导模型训练。否则就是作弊!
K-Fold Cross Validation
我们常用的一个交叉验证方法叫 K-Folf Cross Validation。
以 5-Folf Cross Validation 为例:我们把训练数据均分成五份,每次循环时,将其中一份作为验证数据。比如下图所示,假设初始 \(\lambda = 1\),在训练数据上训练后,用验证数据验证准确率 \(f_1\);第二轮蕾丝,得到准确率 \(f_2\);……;最后得到准确率 \(f_5\)。最后计算出,当 \(\lambda = 1\) 时,平均准确率为 \(\frac{f_1+f_2+f_3+f_4+f_5} {5}\)。以此类推,我们分别给 \(\lambda\) 不同值,然后计算准确率,看什么时候最大,得到最好的 \(\lambda\)。

实践中,数据不多时,我们倾向于把数据分得更多,这样样本也就越多。
这里有一个问题,我们怎么选择合适的候选 \(\lambda\) 呢?
Grid Search
最简单粗暴的循环:
1 | for lambda_1 in [0.01, 0.05, 0.1]: |
这个好处是:因为参数之间互不干扰,所以计算完全可以并行化。坏处是:指数级增长的复杂度。
启发式搜索 Heuristic Search
随机搜索 Random Search
- \(\lambda_1 \in (0.001, 0.1)\)
- \(\lambda_2 \in (0.01, 0.5)\)
- 随机选出 \((\lambda_1, \lambda_2)\) 的组合
遗传算法 Genetic/Evolutionary Algorithm
略。
贝叶斯优化 Bayesian Optimization
略。
模型复杂度
刚刚提到的正则化,其实是在解决过拟合问题。在讲过拟合之前,先了解一下什么叫模型复杂度(Model Complexity)。
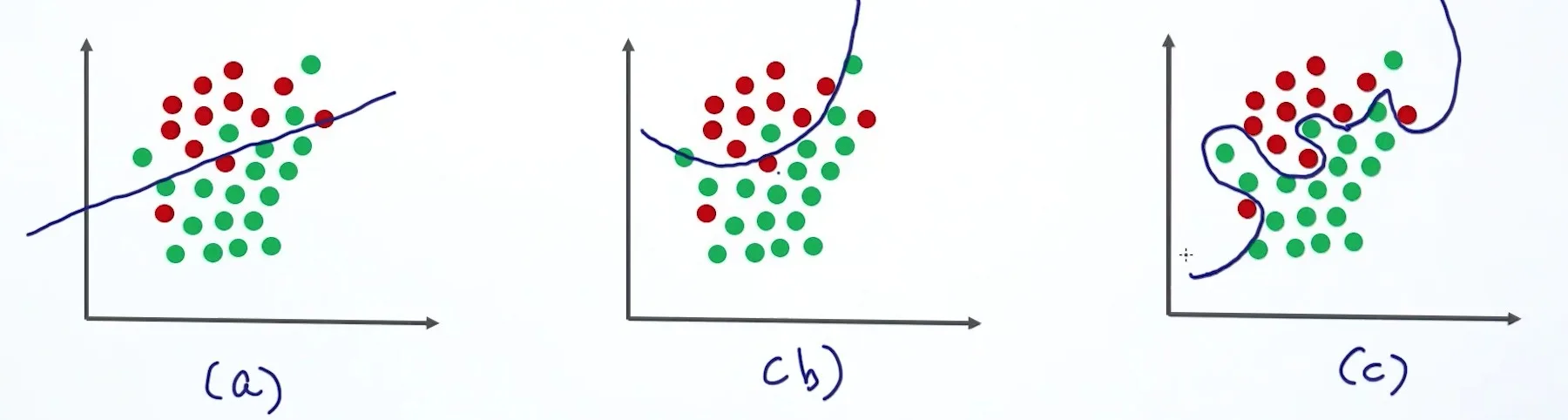
对于相同的训练集,上面三个模型,模型复杂度依次递增。哪个分得最好呢?很多人觉得是 (c)。然而,事实上,这个模型可能对这个训练集拟合很好,但是在面对测试集时,却可能表现十分糟糕。(我们也称这种模型是「不稳定的」。)在 (a) 和 (b) 中, (b) 会相对更好。
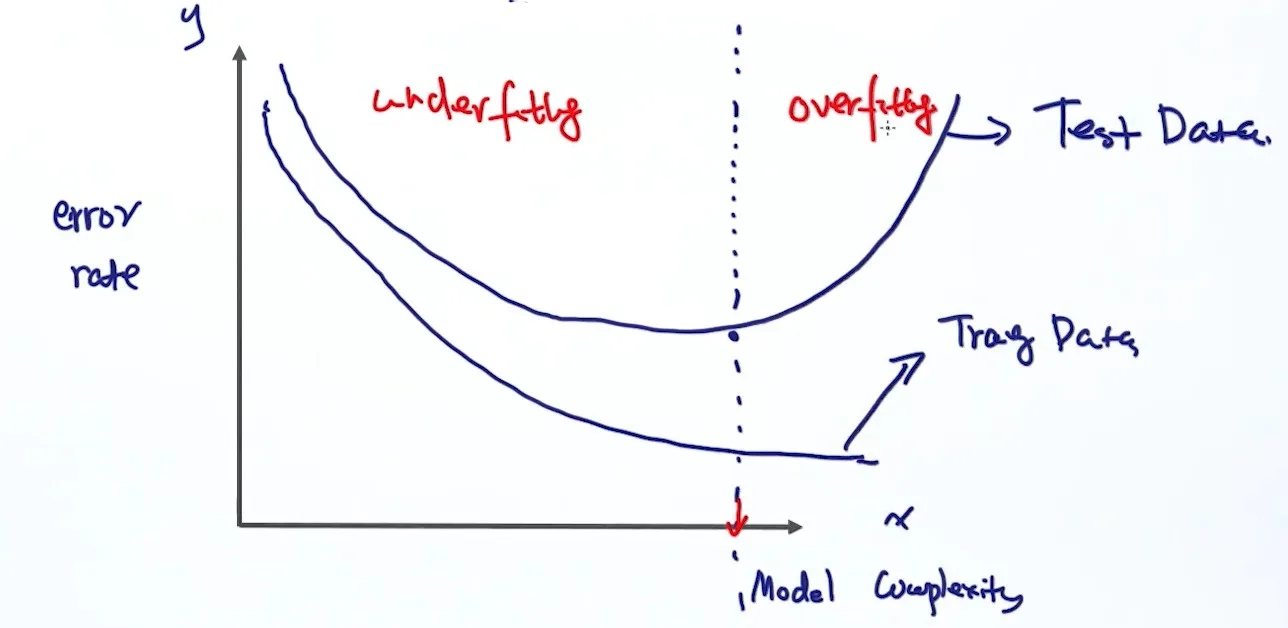
影响模型复杂度的因素
模型的种类
模型选择有不少:
- Linner Regression
- Support Vector Machine
- Neural Network
- Deep Learning
- ...
具体的选择要根据场景。简单模型适合简单环境,复杂模型适合复杂环境。比如,预测明年公司财政情况,算是简单环境;无人驾驶则算很复杂了。
模型的参数个数
比如在神经网络中,layers 的 hidden units 个数。
模型的参数的选择空间
缩小或限制模型参数的选择空间,也可以减少模型复杂度。上面提到的正则就是方式之一。
样本数量
模型的复杂度怎样算合理呢?一般来说,和样本数量是呈正相关的。样本数量越多,模型就越值得复杂;反之,模型应该更简单。
所以如果过拟合了,可以简单粗暴地试着多去获取一些样本。
模型泛化能力
泛化能力(Generalization Capability)是机器学习最核心的点。我们都希望能构建一个应用场景丰富的模型,至少在未来的数据上表现很好。这也是这个模型的价值所在。
简单模型泛化能力高,准确率低;复杂模型泛化能力低,准确率高。
过拟合
在训练集上表现很好,但在测试集上表现很差的现象,叫过拟合。
一个现实中的例子:你的公司为几家企业开发 2B 产品,如果对某个公司特别定制,会导致产品成本高、可复用性低。
为了防止过拟合现象,我们会倾向选择泛化能力较强的模型,也就是复杂度简单的模型。(具体做法请看上述的「影响模型复杂度的因素」。)
非凸函数
如何处理非凸函数呢?
案例:最小集合覆盖问题
举个例子,最小集合覆盖问题(Set Cover Problem)。假设有全集 \(U\) (Universal Set),以及 \(m\) 个子集合 \(S_1,S_2,...,S_m\),如何找到最少的集合,使得找出的集合的并集(Union)等于 \(U\)?
举个例子,\(U=\{1,2,3,4,5\}\),\(S: \{S_1 = \{1,2,3\}, S_2 = \{2,4\}, S_3 = \{1,3\} , S_4 = \{4\} \}\),最少的集合为 \(\{ \{1,2,3\}, \{4,5\} \}\),只需要两个。
方法一:穷举法
穷举法(Exhaustive Search)虽然最简单粗暴,但效率很低。方法是,排列组合出所有可能性,然后选出最优方案即可。
方法二:贪心法
贪心法(Greedy Search)虽然高效,其实不能保证找到全局最优解。方法是,可以先考虑所有子集合,然后尝试一一删除不影响达成目标的子集合。
方法三:目标函数求最优
现在尝试对这个问题进行数学定义:
对于每个 \(S_i\),我们设 \(S_i \to x_i \in \{0,1\}\),当 \(x=0\) 时,选择 \(S_i\),否则不选。这样我们就有一个目标函数了: \[ \underset{}{\operatorname{min}}\sum^m_{i=1} x_i \] 并且考虑到最终需要覆盖 \(U\),所以就有条件:对于任意 \(e\in U\), \(\sum_{i:e\in S_i} x_i \gt 1\)。
关于 \(i:e\in S_i\),表示包含 \(e\) 的所有子集合 \(S_i\) 的下标 \(i\) 的集合。比如 \(e=3\) 时, \(i:e\in S_i = \{1,3,5\}\)。
综上,这个问题的数学形式就是: \[ \begin{array}{l}{\text { minimize } \sum_{i=1}^{m} x_{i}} \\ {\qquad \begin{array}{l}{\text { s.t. } \sum_{i: e \in S_{i}} x_{i} \geq 1} \\ {x_{i} \in\{0,1\} \quad i=1, \ldots, m}\end{array}}\end{array} \] 那么这个函数是凸函数嘛?凸函数的一个性质是定义域是凸集,而 \(x_i \in \{0,1\}\) 显然不是。所以它不是凸函数。
因为定义域的不连续,这个问题实际上是个 integer linear programming 问题,较难在有限时间内拿到最优解。但可以把这个问题松弛化(Relaxation)后求到一个近似解(Approximation)。松弛的方法就是把定义域「连续化」,令 \(x_i \in [0,1]\)。最终求出来再四舍五入 \(x_i\) 到 \(0\) 或 \(1\)。